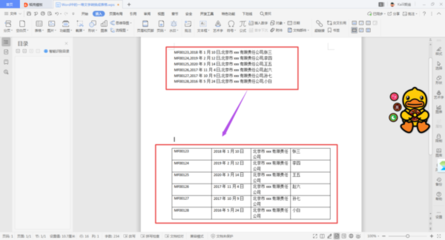
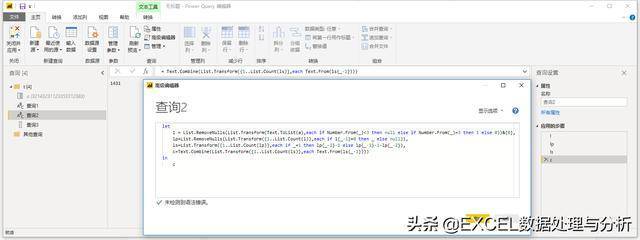
text函数转文本

在数据处理和分析的领域中,将文本(text)转化为数字是一项至关重要且应用广泛的技术。在实际的各类业务场景和数据处理流程里,我们所面对的数据形式多种多样,其中文本数据占据了相当大的比例。计算机在进行运算和分析时,更擅长处理数字。因此,把文本转化为数字就成为了连接现实数据与计算机高效处理之间的关键桥梁。
从本质上来说,文本转化为数字是一个将自然语言表示形式转换为计算机能够理解和处理的数值形式的过程。这一过程涉及到诸多不同的方法和策略,每种方法都有其独特的应用场景和优势。
其中,最简单直接的方法之一是独热编码(One - Hot Encoding)。这种方法适用于处理类别型的文本数据,例如性别(男、女)、颜色(红、绿、蓝)等。在独热编码中,每个类别都会被表示为一个二进制向量,向量的长度等于类别的总数,并且只有对应类别的位置为 1,其余位置都为 0。以颜色为例,如果有红、绿、蓝三种颜色,那么红色可以表示为 [1, 0, 0],绿色表示为 [0, 1, 0],蓝色表示为 [0, 0, 1]。这种编码方式简单直观,能够清晰地将类别信息转化为数字形式,便于计算机进行后续的分类和聚类分析。
另一种常见的方法是词袋模型(Bag of Words)。该模型的核心思想是将文本看作是一个由词汇组成的集合,不考虑词汇的顺序,只关注每个词汇在文本中出现的频率。具体操作是先构建一个词汇表,包含所有文本中出现的词汇,然后对于每一篇文本,统计每个词汇在其中出现的次数,形成一个向量。例如,在一个包含“苹果”“香蕉”“葡萄”三个词汇的词汇表中,一篇文本“苹果 苹果 香蕉”就可以表示为 [2, 1, 0]。词袋模型的优点是简单易懂,能够快速地将文本转化为数字向量,在文本分类和信息检索等领域有着广泛的应用。
除了上述方法,还有基于深度学习的方法,如词嵌入(Word Embedding)。词嵌入是一种将词汇映射到低维向量空间的技术,它能够捕捉词汇之间的语义关系。例如,“国王”和“王后”在语义上有紧密的联系,通过词嵌入技术,它们在向量空间中的距离会比较近。常见的词嵌入模型有 Word2Vec、GloVe 等。这些模型通过在大规模的文本数据上进行训练,学习到词汇的分布式表示,使得具有相似语义的词汇在向量空间中具有相似的表示。词嵌入在自然语言处理的多个任务中都取得了很好的效果,如机器翻译、情感分析等。
将 text 函数转化为数字在实际应用中有着巨大的价值。在商业领域,通过对客户评论、社交媒体数据等文本信息进行数字转化,可以进行情感分析,了解客户的满意度和需求,从而制定更精准的营销策略。在医疗领域,对病历文本进行数字转化,有助于疾病的诊断和治疗方案的制定。在科研领域,对学术文献的文本数据进行处理和分析,可以挖掘出有价值的研究成果和趋势。
文本转化为数字也面临着一些挑战。文本数据具有多样性和复杂性,不同的语言、文化背景下的文本处理方式可能会有所不同。在转化过程中可能会丢失一些重要的信息,例如词汇的顺序和上下文信息。大规模文本数据的处理需要消耗大量的计算资源和时间。
尽管存在这些挑战,但随着技术的不断发展和创新,文本转化为数字的方法也在不断完善和优化。未来,我们可以期待更加高效、准确的文本数字转化技术的出现,为各个领域的数据处理和分析带来更大的便利和价值。通过不断地研究和实践,我们能够更好地利用文本数据,挖掘其中隐藏的信息,推动各个行业的发展和进步。
支付宝扫一扫
微信扫一扫